For about 20 years, I’ve been obsessed with the idea of getting the best score for a machine learning dataset.
It started in postgrad when we would talk about learning algorithms and the problems and datasets we were all using to demonstrate that one algorithm was “better” than another.
A good friend in our research group always pointed out Włodzisław Duch’s work.
Back in the early 2000s, he had a website that listed a suite of the standard ML datasets and the algorithms + configs that achieved the best scores (as reported in published papers), and most importatnyl, the scores they achieved.
For example:
And others.
One cannot look at the tables on the site and think “give me a few days and I could do better…”
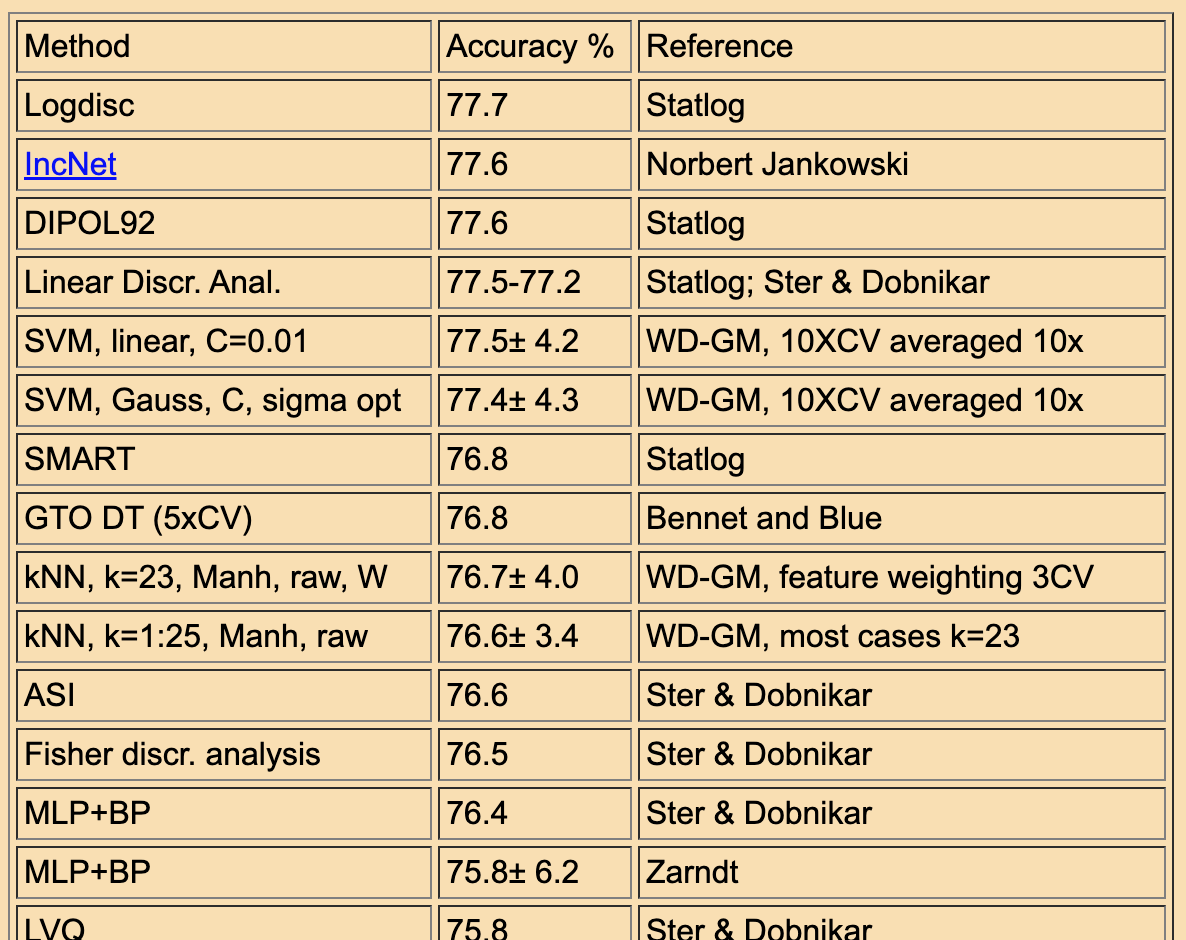
The idea of racing algorithms got into my blood.
I tried to talk myself out of it a few times and wrote articles and tech reports on the evils of “algorithm racing” and the evils of “bad algorithm comparison methodology/stats”.
But, it’s so fun.
I go interested in KDD cups and then later Kaggle, but the “competition” with other people was not what excited me.
Instead, it was the competition with myself. How far could I go? What could I figure out?
I had zero interest in out-performing other participants, but was very interested in the ideas and discoveries they made and shared.
In the end, I was way more interested in reading the forum than in submitting predictions.
Sadly, there was very little sharing culture on kaggle in the early days, although I tried to foster it by giving away sample code, and algorithm implementations, and more back then.
I’ve shared this interest (in best scores for standard datasets) before, long ago in another life. Five years is a long time!
Anyway, I was thinking about this again today.
Why not have a website that lists 10 or so standard datasets in a range of different categories and see how far we can push the scores?
- Datasets are pre-defined and probably pre-cleaned or whatever.
- The metric and test harness is pre-defined.
- People submit a code snippet for an sklearn pipeline that is evaluated and the result stored in a db.
- The “tables” of ranked results are created automatically for each dataset.
- All entries are kept, ranked, and made available to others.
Maybe structure it as a “self guided course”, where each dataset represents a challenge or capture-the-flag where one must achieve a score in the n’th percentile in order to move forward, where the percentiles shift based on how many people have participated so far and how well they have done. Maybe you can’t see all other solutions until you’ve cleared the challenge. Might be fun!
I suspect xgboost or similar will rise up and that in the end it will devolve into grid/random searching hyperparameters for lucky configs or seed hacking for lucky random number seeds.
So what? It might still be fun.
Especially if we can incentivize away from the “find a lucky config” solution and toward a “pass this challenge”.
Maybe just code it up as a prototype and play with it myself?