I’m a hobby quake archivist.
Over the last few years, I’ve been maintaining the Quake Bot Archive.
It is/was a rewarding project filled with nostalgia and writing code to scrape+index+search the internet archive.
Here’s a screenshot:
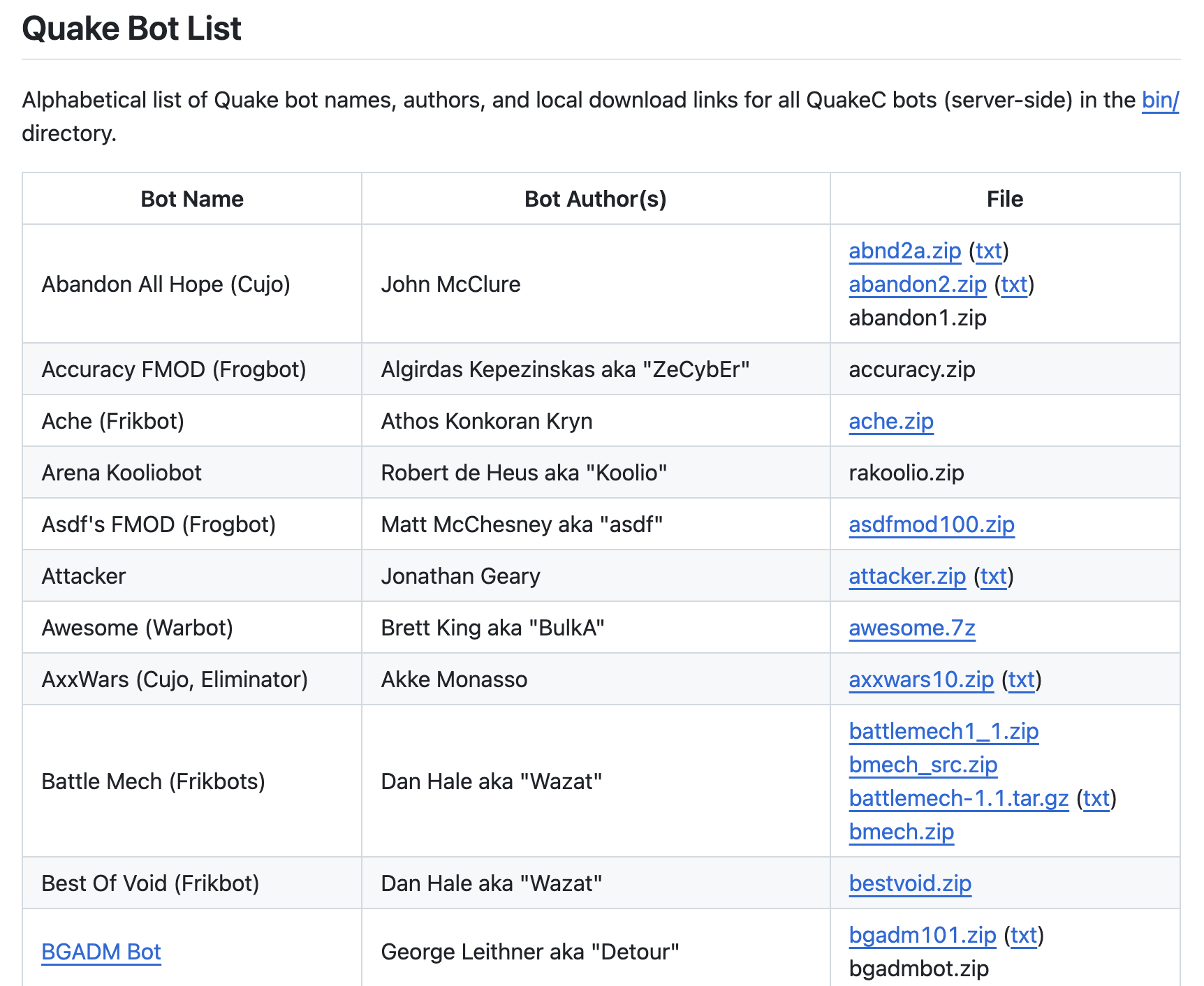
I think I’ve taken the project pretty close to the edge.
- I emailed every single bot author I could find in all the old docs (think a massive spreadsheet of email addresses and current follow-up status, a client management system basically).
- I tracked down modern contact info for most bot authors and reached out.
- I carefully research the history of most bots to ensure I knew exactly what files were released (e.g. quake bot essays and quake bot chronology and quake bot genealogy much more).
- I maintained wishlists of wanted files and wishlists of broken URLs where wanted files were known to exist at one time.
- I kept expanding the scope from bots, to mods that had bots, to proxy bots/aimbots/server-side bots, and on.
- I posted to the community many times kindly asking for the old timers to check their old backup CDs.
- I searched usenet archives, mail archives, internet archives, warez archives, shovelware archive, etc.
- I indexed all files on all old quake addon cds.
- I indexed the files on all of the old quake webpages on the internet archive.
- And more…
{kind=link}
I used the same methods to build other archives, like the official quake archive which led me to many more helpful resources and generated many more ideas on how/where to search.
Now that these Quake 1 archive projects are coming to an end, I was thinking:
Should I archive Quake 2 stuff?
Specifically:
Should I create a Quake 2 Bot Archive?
I think it would be equally as fun.
I played a hell of a lot of Quake2 in the late 1990s. And a hell of a lot of bots. Eraser from memory.
I also developed my own bots back then (lost to time) and hacked out Quake2 AI bot tutorials, like Ecosystem: Constructing a simple self-perpetuating society of adaptable agents (archived).
It might also be interesting to other Quake Archivists / Quake Nostalgia-Fiends :)
Here’s some ad hoc thoughts on how I’d do it:
- Reuse the same procedures and tools and URL index databases developed above as a starting point.
- Carefully research every bot added to the archive to know the full scope of released files.
- Maintain a release chronology essay for each bot added to the archive, to ensure nothing is missed.
- Email every bot author, without fail + track down modern contact info (linkedin/twitter/etc).
- Post to all Q2 communities in an effort to shake loose hard to get files, test releases, etc. on private backups.
- Update the QuakeArchiveSearch to use a URL hash for filenames, to avoid re-downloading/re-scraping files when the internet archive window in follow-up searchers is shifted around.
This last one will be really good. I’ve been thinking about it for ages because the internet archive indexer runs day and night indexing tens of millions of URLs. There’s a lot of room to remove redundancy there.
Maybe it would be a catalyst to finally develop/write/build-out the series of quake bot books I’ve been thinking about for the last 15+ years.
Especially now that we have great LLMs that can help me understand the old code at the drop of a hat.