Stacking or Stacked Generalization is an ensemble machine learning algorithm.
I’ve been obsessed with it since I discovered it as part of the Weka in the late 1990s and reading about it in the Weka “Data Mining” book at the same time.
From the 2016 edition:
Stacked generalization, or stacking for short, is a different way of combining multiple models. Although developed some years ago, it is less widely mentioned in the machine learning literature than bagging and boosting, partly because it is difficult to analyze theoretically and partly because there is no generally accepted best way of doing it—the basic idea can be applied in many different variations.
– Page 497, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
Stacking was also a massive part of the million dollar netflix prize that I followed closely, although they called it blending (e.g. use of a linear model as the meta learner).
Our RMSE=0.86432 solution is a linear blend of over 100 results.
– The BellKor 2008 Solution to the Netflix Prize
I’ve written about this algorithm many times, including how to code it from scratch, how to use it in sklearn, how to use it with neural nets, and how do blending.
Nevertheless, I cannot shake it loose.
More recently, I’ve been reading about how stacking is the heart of autogluon, unlike most other automl frameworks that focus on hyperparameter operation instead.
Unlike existing AutoML frameworks that primarily focus on model/hyperparameter selection, AutoGluonTabular succeeds by ensembling multiple models and stacking them in multiple layers. Experiments reveal that our multi-layer combination of many models offers better use of allocated training time than seeking out the best.
– AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
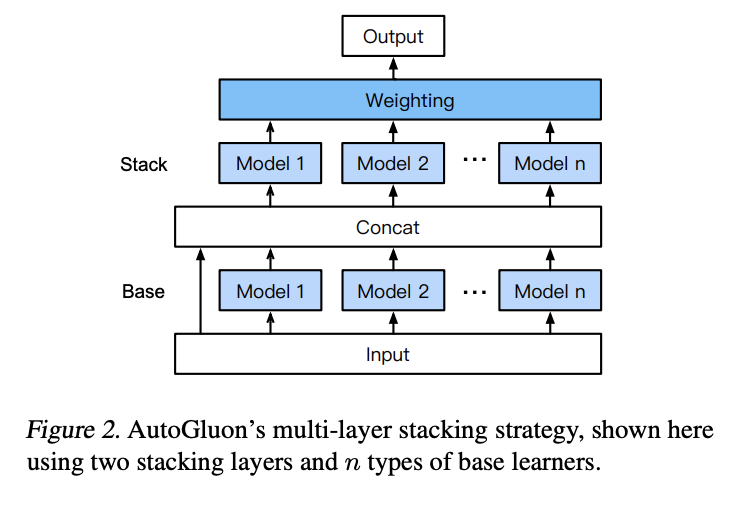
Specifically, autogluon uses a hierarchy of stacked models they refer to as a “multi-layer stack ensemble”.
We additionally introduce several novel extensions that further boost accuracy, including the use of skip connections in both multi-layer stack ensembling and neural network embedding, as well as repeated k-fold bagging to curb overfitting.
– AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
And:
Multi-layer stacking feeds the predictions output by the stacker models as inputs to additional higher layer stacker models. Iterating this process in multiple layers has been a winning strategy in prominent prediction competitions. However, it is nontrivial to implement robustly and thus not currently utilized by any AutoML framework. AutoGluon introduces a novel form of multi-layer stack ensembling, depicted in Figure 2. Here the first layer has multiple base models, whose outputs are concatenated and then fed into the next layer, which itself consists of multiple stacker models. These stackers then act as base models to an additional layer.
– AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
And the pic from the paper:
All these years later, stacking remains incredibly powerful. More so than so much hyperparameter optimization that seems to remain the focus of the field.
This got me thinking over the Christmas break: should I do more on stacking?
Perhaps a dedicated site or book?
Here’s a sketch of the table of contents a small book (~200 pages) on stacking for data scientists might look like:
Table of Contents
Introduction
- What is Stacking (Stacked Generalization)?
- History and Evolution of Stacking
- Why Use Stacking in Machine Learning?
- Overview of Book Structure
Chapter 1: Fundamentals of Stacking
- Core Concepts of Stacked Generalization
- How Stacking Differs from Bagging and Boosting
- The Role of Base Models and Meta-Models
- Advantages and Limitations of Stacking
Chapter 2: Building a Stacking Framework from Scratch
- Designing the Stacking Architecture
- Implementing Base Models
- Creating the Meta-Model
- Training and Cross-Validation for Stacking
- Common Pitfalls and Debugging Tips
Chapter 3: Stacking with scikit-learn
- Overview of scikit-learn’s
StackingClassifierandStackingRegressor - Step-by-Step Implementation
- Tuning Hyperparameters for Stacking
- Practical Examples and Use Cases
- Overview of scikit-learn’s
Chapter 4: Advanced Stacking Techniques
- Multi-layer Stacking (Hierarchical Stacking)
- Feature Engineering for Stacking
- Blending vs. Stacking: When to Use What
- Handling Imbalanced Data in Stacking
Chapter 5: Automating Stacking with AutoML
- Overview of AutoML Frameworks
- Introduction to AutoGluon
- Stacking in AutoGluon: Hands-on Guide
- Comparative Analysis with Other AutoML Tools
Chapter 6: Evaluating Stacking Models
- Metrics for Classification and Regression
- Validation Strategies for Stacking
- Visualizing and Interpreting Stacked Models
- Comparing Stacking to Other Ensemble Methods
Chapter 7: Real-World Applications of Stacking
- Stacking in Kaggle Competitions
- Use Cases in Industry (Finance, Healthcare, etc.)
- Success Stories of Stacked Models in Practice
Chapter 8: Best Practices and Future Trends
- Tips for Efficient Stacking
- Integrating Stacking into Production Pipelines
- Challenges and Emerging Trends in Stacking
- Stacking with Deep Learning Models
Appendices
- Code Samples and Templates
- Key References and Further Reading
- Glossary of Terms
It would be a lot of fun to write.
Like most niche topics, no one will care much or read it.
I outline it here in an attempt to purge a dissuade myself of the idea :)